
Security‑Operations leben heute von Tempo und Kontext. Wer Angriffe rechtzeitig erkennen und sauber eindämmen will, muss Signale aus Identität, Endpunkten und Cloud‑Ressourcen zusammenführen, analysieren und die Reaktion möglichst weitgehend standardisieren. Genau hier setzt Microsoft Sentinel an: ein Cloud‑natives SIEM mit integrierter SOAR, gebaut auf Azure Monitor / Log Analytics. Logs und Alerts landen in einem zentral Speicher, KQL liefert die Erkennung, Incidents strukturieren die Arbeit und Playbooks orchestrieren die Erstreaktion – heute zunehmend im Microsoft Defender‑Portal, das die Sentinel‑Erfahrung vereinheitlicht und mit Defender‑XDR enger verzahnt (inkl. Primary‑Workspace‑Modell).
Dabei analysiert und die schützt die Software – nur weil sie selbst auf Basis von Microsoft-Cloud-Diensten gebaut ist – keineswegs nur Ihre M365- und Azure-Services, sondern nahezu jede-Drittanbieter-Lösung die einen passenden Connector liefern kann und das sind anno 2026 mit 456 Einträgen im Sentinel-Content-Hub verdammt viele. Dieser Beitrag geleitet Sie durch Funktionsumfang, Einordnung, Bereitstellung und Nutzung anhand eines einfachen Beispiels.
Was Sentinel ist
Microsoft Sentinel ist kein weiteres Log‑Sammelbecken, sondern Cloud‑natives SIEM und SOAR
- SIEM heißt: sicherheitsrelevante Signale aus Identitäten, Endpunkten, Cloud‑Ressourcen und Dritttools werden an einem Ort zusammengeführt, normalisiert und mit KQL analysiert.
- SOAR bedeutet: aus Erkenntnissen werden reproduzierbare, automatisierte Reaktionen – vom Kommentar am Incident über Benachrichtigungen bis hin zu Remediation‑Schritten.
Diese Doppelrolle funktioniert so gut, weil Sentinel auf einem Log Analytics Workspace aufsetzt: Alle Daten, die wir aus Quellen einspeisen, landen dort und werden zur Grundlage für Abfragen, Analytik und Vorfälle (Incidents) im Portal. Genau diese Kopplung – Azure Monitor Logs und Sentinel – zeigt sich beim Arbeiten mit Sentinel allenthalben. Die Abfrage‑Engine ist Microsofts Kusto Query Language (KQL), die Tabellen heißen „AuditLogs“, „SigninLogs“, „SecurityAlert“ & Co und der Regel‑Assistent macht letztlich nichts anderes, als regelmäßige KQL-Abfragen ausführen.
Zweck und Funktionsweise
Im Kern macht Sentinel Folgendes: Es sammelt Daten aus Microsoft‑Diensten (z. B. Entra, Defender‑Familie), Azure‑Ressourcen (Activity/Diagnostics) und Drittanbietern (Syslog/CEF/API), speichert sie im Log‑Analytics‑Workspace und setzt darauf Detection und Response auf. Die Einrichtung bleibt bewusst simpel:
- Log Analytics Workspace (LAW) anlegen
- Sentinel aktivieren
- Diagnostic settings in Entra (und ggf. Azure‑Ressourcen) auf diesen LAW zeigen lassen
Fertig ist die Baseline. Wer Drittquellen anschließt, nutzt AMA/Syslog/CEF oder APIs. Azure-Aktivität lässt sich über eine Azure-Policy anbinden. Aber von Grundsatz her war´s das, was die Bereitstellung betrifft und überdies unterstützt die jeweilige Connector-Seite jeweils das Onboarding.
Nach dem initialen Setup allerdings sind Ingestion‑Latenzen möglich; Microsoft nennt als Worst‑Case beim initialen Verdrahten bis zu drei Tage. Im Alltag sind es eher Minuten. Lookback‑Zeiträume in Ihren Regeln sollten das aber abfedern.
Einrichtung: Azure Portal vs. Defender-Portal
Hat der Workspace erst Takt, aktivieren Sie auf diesem Microsoft Sentinel. Ab hier spricht man im Betrieb vom „Sentinel‑Arbeitsbereich“, auch wenn technisch weiterhin der Log‑Analytics‑Container darunter liegt. Sentinel liefert dann quasi das Incident‑Modell und die Automation; Sie bauen Analytics‑Regeln (Scheduled, Microsoft Security Rules, Fusion/ML), definieren Entity‑Mappings und lassen die Ergebnisse als Incidents materialisieren.
Microsoft ist seit einigen Monaten dabei, Funktionen aus dem Sentinel-Blade im Azure-Portal (quasi dem Sentinel-aktivierten Log Analytics Workspace) ins Defender-Portal zu verlagern, d. h. Sie untersuchen Vorfälle heute zunehmend im Microsoft Defender‑Portal, das die Sentinel‑Experience aufnimmt und mit den Defender‑XDR‑Signalen verknüpft.
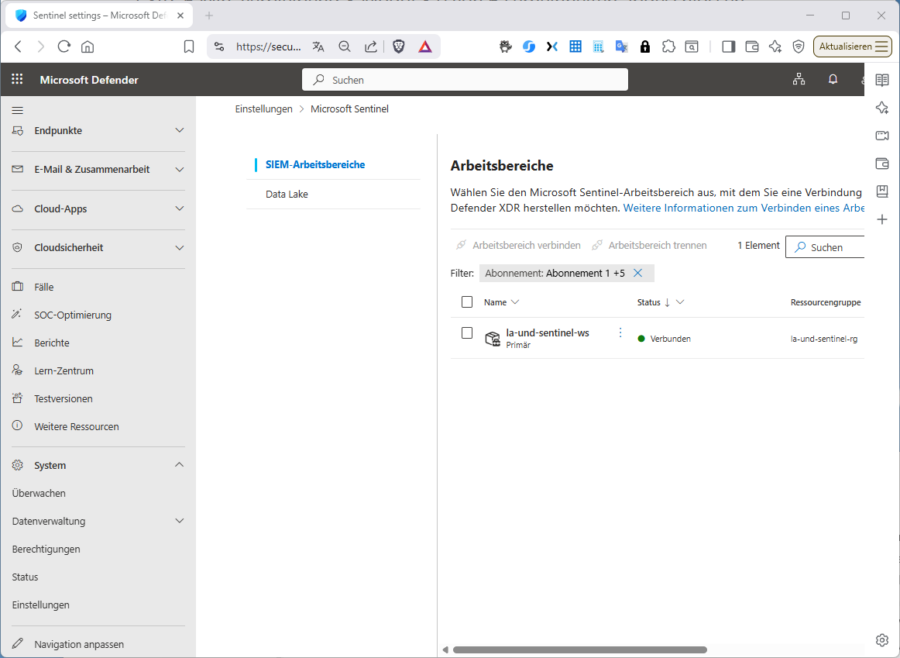
Die Regel‑Erstellung und das Entity‑Mapping bleiben aber die dieselben wie bei Sentinel im Azure-Portal, nur die Oberfläche wird einheitlicher und damit die Zusammenarbeit zwischen Identität, Endpoint, Mail, SaaS und Cloud‑Ressourcen spürbar effizienter. Sie können übrigens die Verknüpfung von Sentinel und Log Analytics auf im Defender-Portal sehen, bzw. von hier aus anstoßen. Sie finden die Einstellungen unter „System / Einstellungen / Microsoft Sentinel /SIEM / Arbeitsbereiche“.
Komponenten
Trotzdem steht für manche Nutzer häufig die Frage im Raum, was „wo“ erstellt und konsumiert wird. Am besten stellt man sich den Sentinel als eine Lösung mit zwei Schichten vor:
- Ressourcen‑Schicht in Azure (wo Dinge existieren) und
- SecOps‑Schicht im Defender‑Portal (wo Analysten arbeiten).
In Azure (Ressourcen‑Schicht) „bauen“ Sie das Fundament. Dazu gehört:
- Log Analytics Workspace (LAW) pro Region/Subskription. Hier landen die Daten, hier läuft KQL. Auf diesem LAW aktivieren Sie Microsoft Sentinel (technisch: die SecurityInsights / Sentinel‑Lösung wird mit dem Workspace verbunden).
- Datenflüsse: Je nach Connector-Typ müssen Sie sich noch um die Datenflüsse kümmern. Bei unserem späteren KQL-Beispiel werden wir ungewöhnliche Entra-Rollenhochstufungen untersuchen. Datenqelle ist dann Microsoft Entra ID. Dieses binden Sie manuell über ein „Diagnostic settings“ im Entra‑Admin-Center oder automatisiert, über die zugehörige Connector-Page (siehe unten) an. In unserem Fall senden wir AuditLogs, SigninLogs, ggf. ServicePrincipalSignInLogs in einen LAW. Sie können auch mehrere Diagnostic‑Settings anlegen; pro Setting ist je ein LAW wählbar. So können Sie parallel in verschiedene Workspaces (auch in anderen Subscriptions) schreiben.
- Optionale Ressourcen: Logic Apps (Playbooks), AMA/DCR für Syslog/CEF/VMs etc. sind allesamt Azure‑Ressourcen, die Sie in den RGs/Subskriptionen ihrer Wahl anlegen. (Die Playbooks nutzen wir dann später im Kontext von Automation Rules.)
Defender‑Portal (SecOps‑Schicht): Hier „arbeiten“ Sie mit dem SIEM, d. h. Incidents, Analytics‑Regeln, Automation Rules, Playbooks – der gesamte SOC‑Arbeitsablauf lebt hier, inklusive Investigation.
Achtung: Falls Sie mehrere Workspaces haben oder die Sentinel-Verknüpfung von einem „alten“ auf einen „neuen“ Workspace verlagern wollen, beachten Sie Folgendes: Mehrere Sentinel‑Workspaces pro Tenant sind zwar möglich, Sie müssen aber das Konzept „primärer Workspace“ vs. „sekundärer Workspace“ verstehen: Im Defender‑Portal wählen Sie einen „Primary Workspace“. Viele „tenant‑weite“ Microsoft‑Konnektoren (Defender‑Signale, Entra‑Schutz u. ä.) hängen nur am Primary‑Workspace; sekundäre Workspaces werden für diese Signale automatisch entkoppelt, um Duplikate zu vermeiden. Möchten Sie ihre Datensammel-Basis also „verlagern“, ändern Sie den Primär-Arbeitsbereich im Defender‑Portal, denn im Defender‑Portal sind tenant-basierte Microsoft‑Konnektoren (inkl. Entra‑/Defender‑Konnektoren) immer an den Primär‑Workspace gebunden.
Fassen wir die einzurichtenden Komponenten zusammen: der Log Analytics Workspace dient als Speicher und „KQL‑Motor“; Microsoft Sentinel dient als SIEM/SOAR‑Funktionsebene; der Content Hub ist ein Katalog für vorkonfektionierte Lösungen, die …
- Data Connectors,
- vorkonfigurierte Regelsätze,
- Workbooks
- Automation Rules, bzw. „Playbooks“ (Logic Apps), welche die Reaktion standardisieren
… bündeln. Die Palette hier verfügbarer Data Connectors gliedert sich grob in Microsoft‑eigene (Entra, Defender, M365), Azure‑Quellen (Activity, Ressourcen‑Diagnosen) bis zu Drittanbietern via Syslog/CEF/API. Hier alle einzurichtenden Komponenten:
|
Komponente |
Zweck |
Wichtige Hinweise |
|
Log Analytics Workspace |
Datenspeicher, KQL‑Abfragen |
Pflicht; hier wird Sentinel aktiviert. |
|
Microsoft Sentinel |
SIEM+SOAR, Incidents, Automation |
Bedienung zunehmend im Defender‑Portal. |
|
Data Connectors |
Datenquellen anbinden |
Entra/M365 via Diagnostic settings; Third‑Party via Syslog/CEF/API. |
|
Analytics Rules |
Erkennung (KQL, Entity‑Mapping) |
Incident‑Erzeugung, Gruppierung, Zeitplan. |
|
Automation Rules |
Reaktion steuern |
Empfohlener Weg, Playbooks auszulösen. |
|
Playbooks (Logic Apps) |
Orchestrierung/Response |
Incident‑Trigger, O365 Outlook/Teams/ITSM etc. |
Man kann es auch der Perspektive betrachten, welche Azure-Ressourcen erstellen werden müssen. Einige sind je nach Use Case optional.
|
Ressource |
Pflicht? |
Zweck |
|
Log Analytics Workspace |
✔️ |
Speicherbasis |
|
Microsoft Sentinel aktivieren |
✔️ |
Sentinel-Features aktivieren |
|
AMA (Azure Monitor Agent) |
optional |
wenn Datenquelle ihn benötigt |
|
Logic App |
optional |
wenn SOAR/Playbooks verwendet werden |
|
Azure Storage |
optional |
für lange Aufbewahrung |
|
Machine Learning Workspace |
optional |
falls Notebooks/ML intensiv genutzt werden |
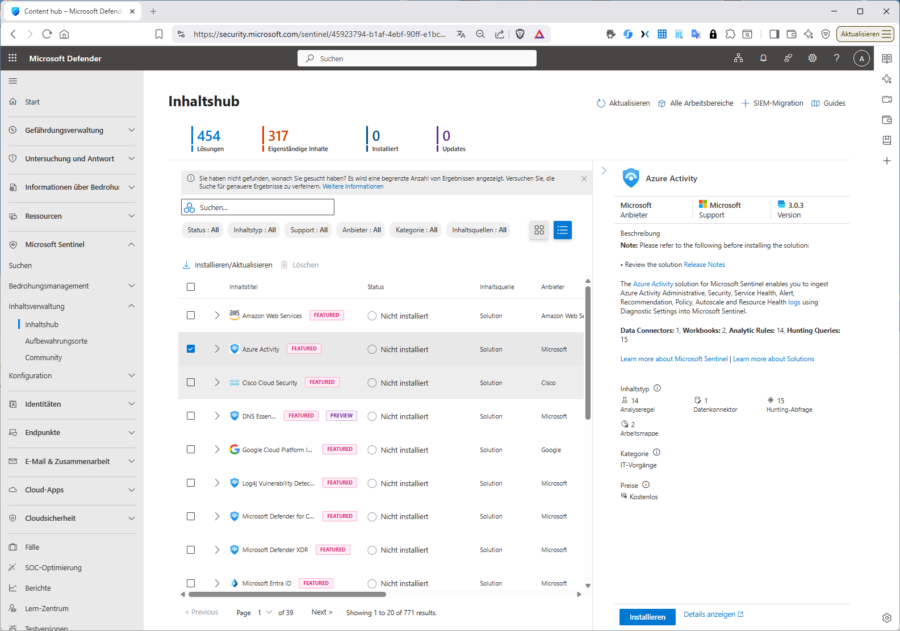
Folgenden Abbildung zeigt den Content-Hub im Defender-Portal. Hier suchen Sie nach anzubindenden „Lösungen“. Der Katalog umfasst derzeit 454-Lösungen von denen sie die meisten mit „Installieren“ installieren könnten.
Lösung versus Connector
Installiert heißt aber noch nicht „verbunden“. Microsoft unterschiedet hier quasi zwischen den Ebenen „Lösung“ und „Connector“, ein Zusammenhang der oft verwirrt. Eine „Lösung“ im Inhaltshub ist ein Paket. Ein „Dataconnector“ ist ein einzelner Anschluss. Eine Lösung kann einzelne oder mehrere Dataconnectors enthalten, aber Connectoren können auch völlig ohne Lösung existieren. Sentinel trennt also Inhalt (Solutions) von Datenanschlüssen (Connectors). Viele Connectors kommen über eine Lösung, aber nicht alle.
Eine Lösung ist also quasi ein Inhalts‑Bundle, dass mehrere Sentinel‑Artefakte enthält, z. B.
- Data Connector(e)
- Analytics Rules (Scheduled, NRT, MSSP‑Rulepacks)
- Hunting Queries
- Workbooks
- Playbooks
- Watchlists
- Parser / Kusto Functions
- Beispiel‑Dashboards & Notebooks
Ein Data Connector ist ein Sammelpunkt im Sentinel‑Portal, der:
- anzeigt, welche Datenquelle angeschlossen werden kann
- beschreibt, wie man sie anschließt
- sagt, welche Tabellen im Log Analytics Workspace befüllt werden
- den UI‑Status anzeigt („Connected / Not Connected“)
Ein Connector kann technisch auslösen:
- Diagnostic Settings (z. B. Entra, Azure Activity)
- API‑Calls (z. B. M365 Defender, Defender for Cloud Apps)
- Agent‑basierte Ingestion (Syslog, CEF, AMA)
- Custom‑Pipeline / ingest‑API (selten)
Sie müssen also nach dem Installieren einer Lösung aus dem Defender-Portal unter „Microsoft Sentinel / Inhaltverwaltung / Inhaltshub“ noch konkret die gewünschten Data-Connectoren verbinden. Das machen Sie unter „Microsoft Sentinel / Konfiguration / Datenconnectors.
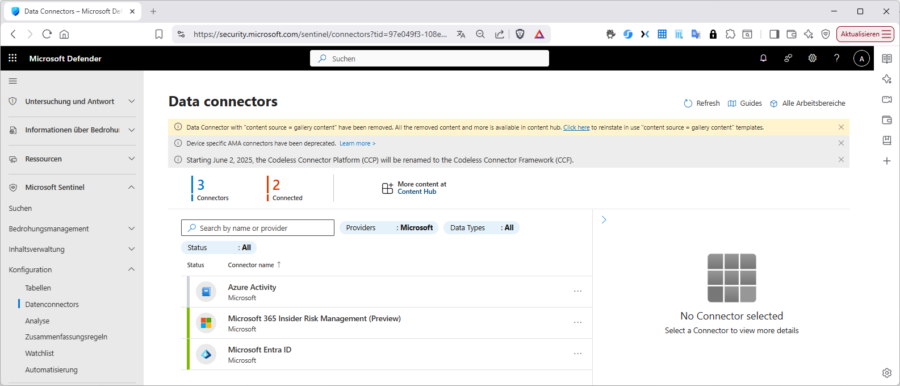
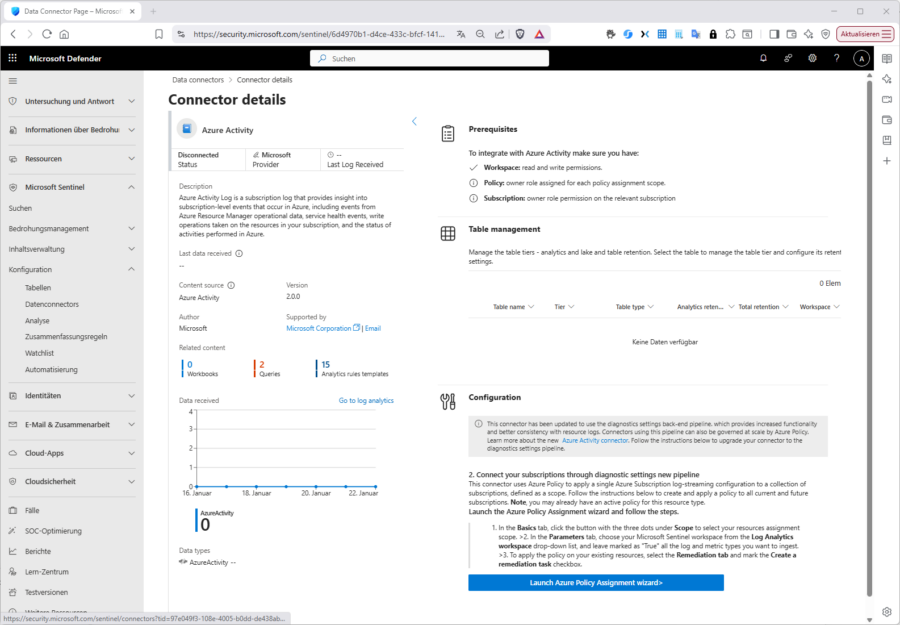
Wie oben bereits erwähnt, kann das über eine Diagnose-Einstellung (Entra), eine Azure Policy (Azure Activity) oder einen Agent erfolgen. Was genau zu tun ist sehen Sie bei „Prerequisites“.
Im Falle von Entra ID müssen Sie die gewünschten Audit- und/oder Signin-Logs per Diagnoseeinstellung abholen. Dazu (für die Diagnose-Einstellungen) sind passende Tenant-Berechtigungen wie „Globaler Administrator“ oder „Security Administrator“ notwendig. Damit jedoch die Diagnostic Settings die Logs in einen LAW schreiben dürfen, benötigen sie auch Zugriff auf den Log Analytics Workspace typischerweise via „Log Analytics Contributor“ oder „Contributor“ auf Workspace-Ebene in Azure (RBAC).
Das Überwachen der Azure-Activität erreichen u. a. Sie durch Durchsetzen einer Azure-Policy. Den zugehörigen Vorgang können Sie direkt von der zugehörigen Connector-Page aus anstoßen.
Kosten
Über Kosten muss man offen sprechen. Sentinel erbt das finanzielle Profil seines Speichers (LAW): Demnach ist Log‑Analytics‑Ingestion pro GB der dominante Hebel, zu dem ein Sentinel‑Aufpreis pro GB kommt. Wer Automation nutzt, hat zusätzlich Logic‑Apps‑Runs im Blick. Das ist fair und transparent – und motiviert, drei Dinge sauber zu tun:
1) Daten bewusst auswählen (nicht „alles“ ungefiltert),
2) Retention/Commitment‑Tiers passend wählen,
3) früh erkennen, welche Tabellen wirklich Wert stiften.
Arbeitsweise und Use Case
Wie arbeitet man nun konkret in/mit Sentinel? Welche Tabellen sind entscheidend? Welche Queries beantworten echte Fragen? Welche Regeln erzeugen Incidents, die wir wirklich behandeln wollen?
In der Praxis startet man mit wenigen, aber belastbaren Detections und skaliert erst, wenn das SOC‑Team den neuen Takt verinnerlicht hat. Und genau hier zeigt sich die Eleganz von Sentinel: Alles ist Query‑first. Als ein Anwendungsbeispiel unter „Tausenden“ wollen wir untersuchen, wann es zu priviligierten Rollen-Hochstufungen im Entra ID kommt.
Dazu schreiben wir zunächst eine passenden KQL-Abfrage, die wir dann später in einer Analyseregel verwenden können. Diese brauchen wir, weil eine Rollen-Hochstufung allein (die wir ja bereits durch manuelle oder automatisierte, KQL-basierte Analyse der Audi-Logs finden können) ja noch kein Grund/Anlass für einen Sicherheitsvorfall sein muss. Wiederholen sich aber solche Vorgänge oder treten in ungewöhnlichen Mustern auf, kann das Grund für eine Incident-Erstellung sein, bei der uns unsere Analyse-Regel hilf. Schlägt der Incident erstmal in Sentinel auf, können wir in komfortabel und interaktiv untersuchen und Schlussfolgerungen ziehen. Die Analyseregel selbst kann übrigens – muss aber nicht – gleich eine automatisierte Resonse beinhalten. Hier kommen dann o. e. Playbooks ins Spiel.
Der Datenfluss beginnt fast immer dort, wo die Signale entstehen. Für Microsoft Entra ID und viele Azure‑Dienste bedeutet das in vielen Fällen, den gewünschten Connector mit Hilfe eines Diagnostic settings an den Workspace zu binden. Hier wählen wir dann die gewünschten Log-Kategorien (Audit, Sign‑ins, Service Principal Sign‑ins usw.) aus, die an den gewählten Log Analytics Workspace fließen sollen. Das ist nicht nur elegant, sondern auch robust, weil Microsoft diese Pfade intern beherrscht; d. h. integrierte Konnektoren werden im Hintergrund bedient, ohne dass wir mit zusätzlichen Agenten jonglieren müssen.
Wichtig ist allerdings, die Latenz realistisch einzuplanen: Während die meisten Tenants in Minutenbereich liegen, weist Microsoft explizit darauf hin, dass beim ersten Aufsetzen der Pipeline bis zu drei Tage vergehen können, ehe Daten stabil im Workspace auftauchen. Das ist kein Fehler, sondern erwartbares Verhalten der Integrationskette und der Grund, warum gut konfigurierte Regeln großzügige Lookback‑Zeiträume wählen, statt nur die letzten zehn Minuten zu betrachten.
KQL basteln
Schauen wir uns den skizzierten Use Case etwas genauer an: die Erkennung privilegierter Entra‑Rollenvergaben. Wie oben erwähnt zwar hochrelevant, aber am Ende „nur“ ein Muster unter vielen. Dazu brauchen wir eine starke Detection, die nicht beim ersten Sonderfall abbricht, und ein sinnvoller Response‑Pfad.
Anlaufstelle für die Erkennung der Vergabe privilegierter Entra‑Rollen sind die AuditLogs im Entra ID. Hier steht in „ActivityDisplayName“ jeweils klar, was passiert ist („Add member to role“, „Activate eligible role assignment“ usw.), in „InitiatedBy“ der Akteur und in „TargetResources“ (als Array) sowohl der betroffene User als auch die Rolle selbst. Genau das entpacken wir, gruppieren die beiden Zeilen pro Vorgang wieder zusammen und projizieren nur die Felder, die wir für „Triage“ und „Automation“ benötigen.
Folgendes KQL basiert auf AuditLogs und berücksichtigt sowohl direkte als auch PIM‑Aktivitäten. Der Clou ist das saubere Entfalten von „TargetResources“ und das Gruppieren per „CorrelationId“, sodass pro Vorgang genau eine Zeile im Ergebnis steht. Damit wird der Schritt zur Praxis leicht:
AuditLogs // Zeitfenster (für Ingestion-Latenz ruhig großzügig wählen) | where TimeGenerated > ago(4h) // Entra-Rollenmanagement-Ereignisse | where Category == "RoleManagement" // Direkte Zuweisungen + PIM-bezogene Activities | where ActivityDisplayName has_any ( "Add member to role", "Add permanent member to role", "Add eligible member to role", "Activate eligible role assignment", "Extend eligible role assignment", "Renew eligible role assignment") // Nur erfolgreiche Vorgänge (robust auf beide Felder) | where tostring(Result) =~ "success" or ResultType == "Success" // JSON-Felder robust konvertieren, bevor wir sie verwenden | extend TargetResources = todynamic(TargetResources), InitiatedBy = todynamic(InitiatedBy) // TargetResources ist ein Array (meist User + Role) → entfalten | mv-expand TR = TargetResources // Typ des Zielobjekts bestimmen (User vs. Role/DirectoryRole) | extend targetType = tostring(TR.type) // Rollenname & Ziel-User abhängig vom Typ extrahieren | extend roleDisplayName = iff(targetType in ("Role","DirectoryRole"), tostring(TR.displayName), ""), targetUserUPN = iff(targetType == "User", tostring(TR.userPrincipalName), "") // Je Vorgang (CorrelationId) wieder zusammenführen | summarize Role = anyif(roleDisplayName, roleDisplayName != ""), TargetUser = anyif(targetUserUPN, targetUserUPN != ""), InitiatedBy = any(tostring(InitiatedBy.user.userPrincipalName)), Activities = make_set(ActivityDisplayName, 10), FirstSeen = min(TimeGenerated), LastSeen = max(TimeGenerated) by CorrelationId // Fokus auf privilegierte Rollen (Namen; alternativ unten GUID-Härtung nutzen) | where Role in ( "Global Administrator","Privileged Role Administrator","Security Administrator","User Administrator", "Exchange Administrator","SharePoint Administrator","Conditional Access Administrator", "Application Administrator","Authentication Administrator","Cloud Application Administrator") | project LastSeen, Role, TargetUser, InitiatedBy, Activities, CorrelationId | order by LastSeen desc
Das funktioniert verlässlich, weil wir exakt die offiziellen Felder nutzen (ActivityDisplayName, TargetResources, InitiatedBy) und sowohl direkte als auch PIM‑Aktivitäten berücksichtigen. Das „mv-expand“ trennt die Doppelstruktur (User/Rolle), „CorrelationId“ verbindet wieder zu einem Vorgang, und das „Lookback“ federt die natürliche Entra‑Latenz ab.
Von KQL zur Regel – und zur Reaktion
Sobald die Query überprüfbar Ergebnisse liefert – kann man z. B. im Workspace und „Protokolle“ im KQL-Editor mit einem „Testfall“ ausprobieren – …
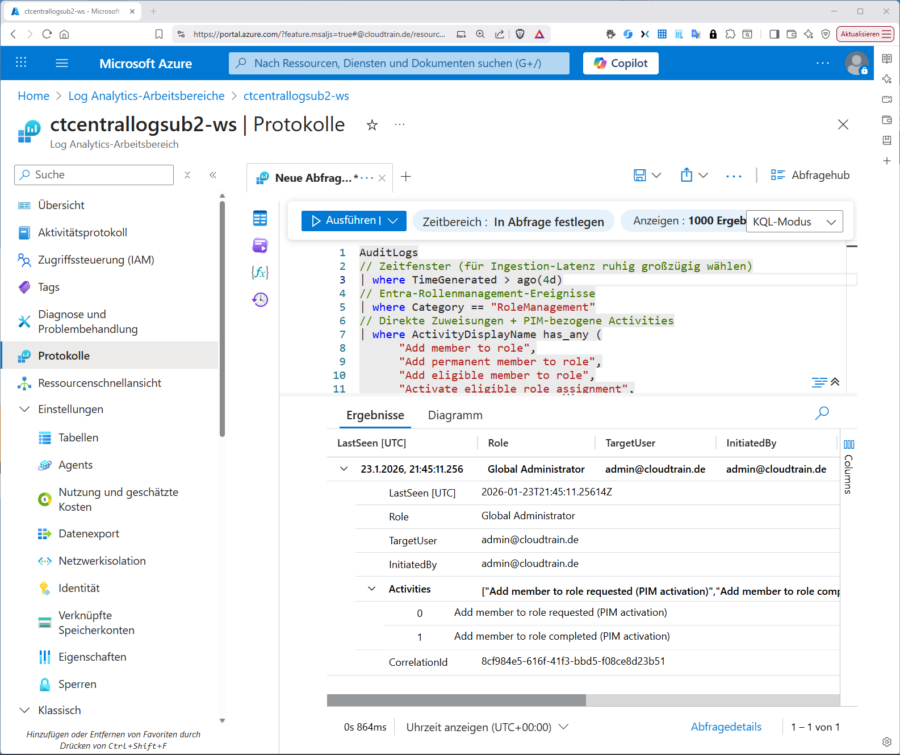
(Sie können aber auch „in“ der Connecor-Page links unten bei „Data recieves“ auf „Go to log analytics“ klicken und ihr Test-KQL dann im Defender ausprobieren – die Navigation vom Defender-Portal aus wäre dann „Untersuchung und Antwort / Suche“.)
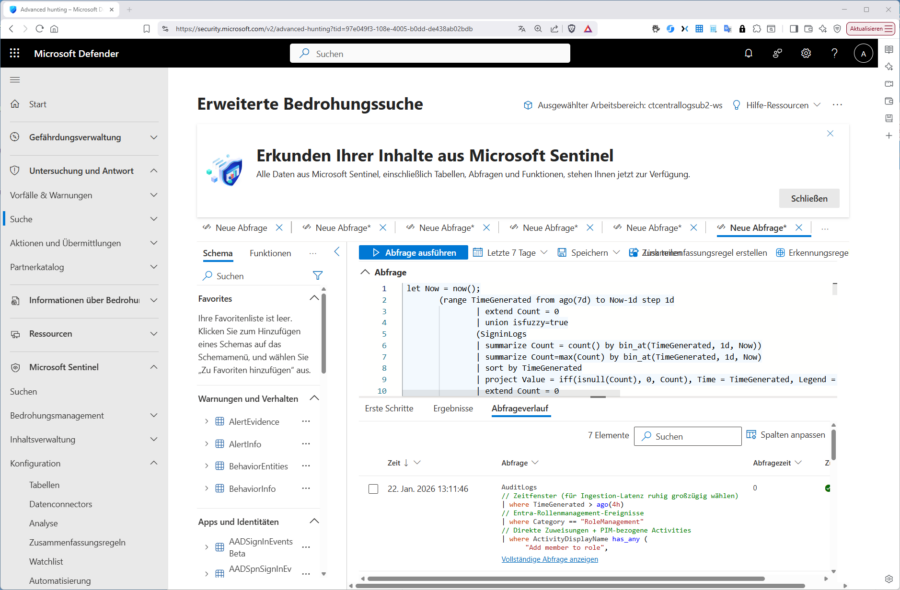
… können Sie in Sentinel beispielsweise eine „Scheduled“‑Rule erstellen, die ihre KQL-Abfrage regelmäßig ausführt (z. B. 1 x pro Tag/Stunde oder im Verdachtsfall alle 5 min), um daraus eine Anomalie und letztendlich einen Vorfall (Incident) abzuleiten.
Diese erstellen Sie ebenfalls seit einiger Zeit im Sentinel-Abschnitt im Defender-Portal unter „Konfiguration / Analyse“. Hier finden Sie übrigens je nach Connector im Tab „Rule templates“ auch eine riesige Palette mitgelieferter Regel-Vorlagen, mit denen Sie natürlich zuerst experimentieren sollten, bevor Sie sich an eigene Regeln machen. Im Falle des Entra-Connectors sind das 73 Stück.
Wir wollen trotzdem das Vorgehen zum Erstellen einer einfachen eigenen Analyseregel demonstrieren, zunächst lediglich eine Regel zur Incident-Generierung, die nur Letzteres tut, aber keine automatische Reaktion (SOAR) anschließt. Jede Analyseregel muss die folgenden Einstellungen/Parameter umfassen:
|
Einstellung |
Empfehlung für diesen Use Case |
|
Run frequency |
5–10 Minuten |
|
Lookup period |
2–4 Stunden (Entra‑Latenz einkalkulieren) |
|
Incident |
„Create incident“ aktivieren |
|
Alert Grouping |
nach CorrelationId gruppieren (ein Vorgang = ein Incident) |
|
Entity‑Mapping |
Account(Target) → TargetUser (UPN), Account(Actor) → InitiatedBy (UPN) |
|
Severity: |
High • Create incident: On |
In der Scheduled‑Regel wählen wir für unser Beispiel eine Frequenz von fünf bis zehn Minuten, ein Lookback von zwei bis vier Stunden (wegen der möglichen Entra‑Latenz), aktivieren die Incident‑Erzeugung, konfigurieren eine Gruppierung nach „CorrelationId“ und mappen die Entities auf „TargetUser“ (Account/UPN) und „InitiatedBy“ (Actor/UPN). In Kurzform durchlaufen Sie dazu folgende Schritte:
1) Regel anlegen
- Microsoft Sentinel → Analytics → + Create → Scheduled query rule
2) General
- Name: Privileged Role Assignment (Entra ID) – Direct & PIM
- Description: “Detects privileged Entra role assignments (direct & PIM: eligible/activate/extend/renew) including target user and initiator”.
- Tactic: Privilege Escalation
- Severity: High
3) Rule logic
- Query: Das o. a. KQL-Dokument
- Run frequency: 5–10 Min
- Lookup period: 2–4 Std
(Hintergrund: Entra‑Audit‑Latenz nach Diagnose‑Setup kann spürbar sein; ein breiteres Lookup vermeidet Fault-Negativs.) - Alert when: Query returns > 0 results
- Alert grouping: Enabled, Group by CorrelationId (fasst die User/Role‑Teillinien zu einem Vorgang zusammen)
4) Entity Mapping (wichtig)
- Account (Target) → TargetUser (UPN)
- Account (Actor) → InitiatedBy (UPN)
5) Incident settings
- Create incident: On
- Grouping window: 1 Std
- Grouping type: All events into a single incident (nach CorrelationId)
Ich habe hier nicht jeden Schritt bebildert, aber die Assistent führt Sie einigermaßen selbsterklärend durch die Regelerstellung: Wichtig ist, dass Sie im Schritt „Set rule logic“ ihr oben erfolgreich getestetes KQL einfügen. Sie können sogar von hier aus noch einmal die Ergebnisse testen:
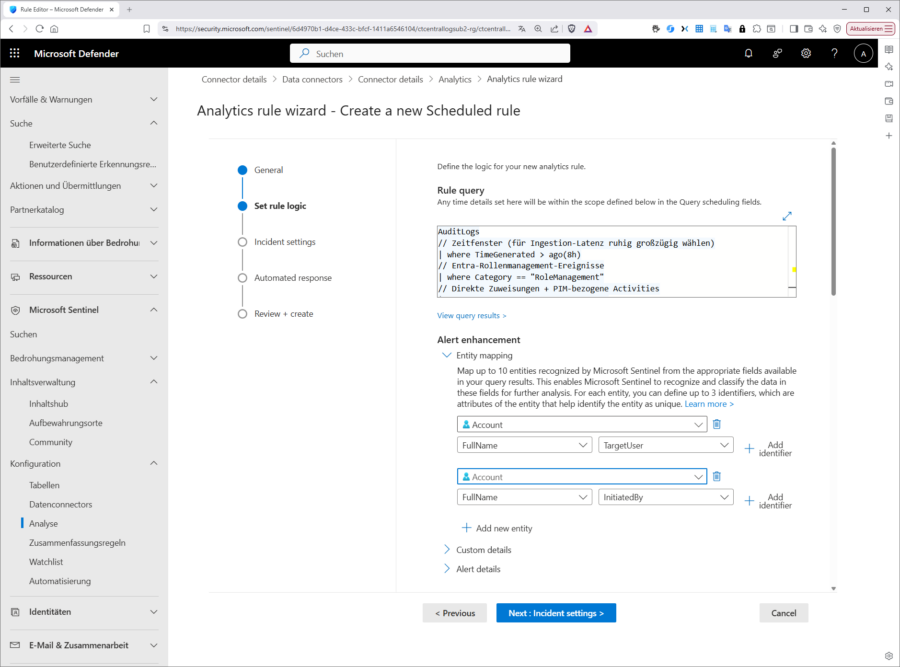
Aber Achtung: Ohne weitere Anpassung detektieren Sie quasi jedes Auftreten einer Rollenhochstufung als Incident,d. h. für ein praxisgerechtes Szenario müssen Sie sich auch mit den Einstellungen bei „Alert treshold“, „Event grouping“ und „Suspression“ auseinandersetzen.
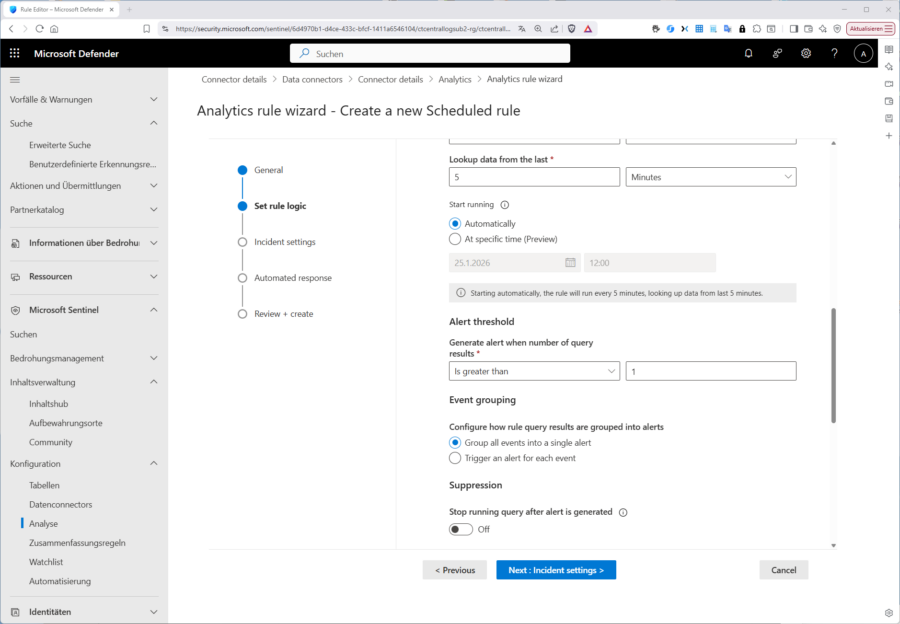
Im Schritt „Incident Settings“ schalten Sie dann die Funktion ein, dass überhaupt ein Vorfall aus ihrer Detektion erzeugt wird und richten falls nötig das passende „Alert grouping“ ein. Wie nehmen als „Grouping-Window“ 1 Stunde und gruppieren alle erfassten Events in „einen“ Vorfall.
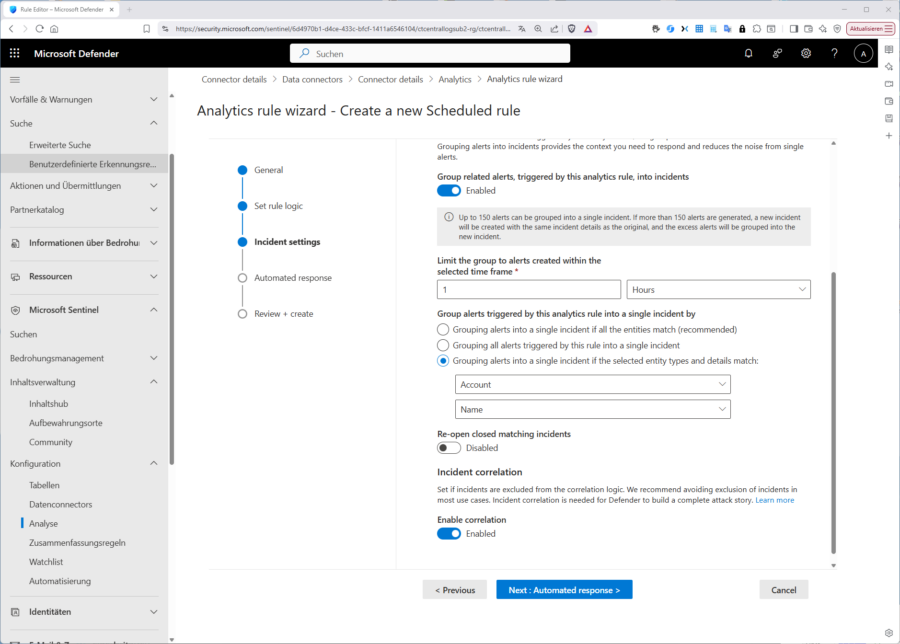
Den letzten Schritt „Automated response“ lassen wir für dieses Beispiel vorerst ungenutzt, Sie hätten aber die Option, ein Playbook anzustoßen oder eine Nachricht abzusetzen.
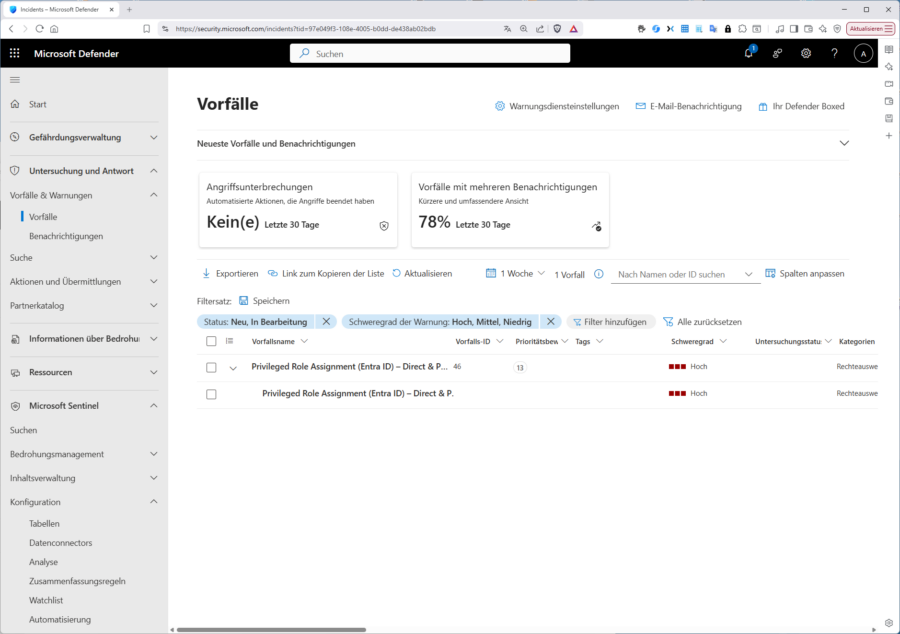
Haben Sie alles korrekt konfiguriert, sollte in absehbarer Zeit im Defender-Portal unter „Untersuchung und Antwort / Vorfälle“ auch der zugehörige Incident aufschlagen:
Automatische Response
Als einfaches Beispiel wollen wir bei Incident‑Erstellung automatisch reagieren. Hier hat Microsoft in den letzten Jahren den Schalter umgelegt. Bis Juni 2023 war es an dieser Stelle üblich, direkt auf ein Playbook zu verweisen: Stattdessen empfiehlt Microsoft heute, „automation rules“ als zentrale Steuerstelle. Diese erlauben das Definieren von Bedingungen, Festlegen von Aktionen und das Auslösen von Playbooks an einer Stelle. Die Migration von „alert‑triggered playbooks“ hin zu „automation“ Rules ist dokumentiert und sollte bei neuen Deployments der Normalfall sein.
Sie können aber alternativ im Defender-Portal unter „Microsoft Sentinel „Automatisch rules“ mit einem Klick auf „Create“ alternativ immer noch direkt „Playbook with incident trigger“, „Playbook with alert trigger“ oder „Playbook with entity trigger“ wählen.
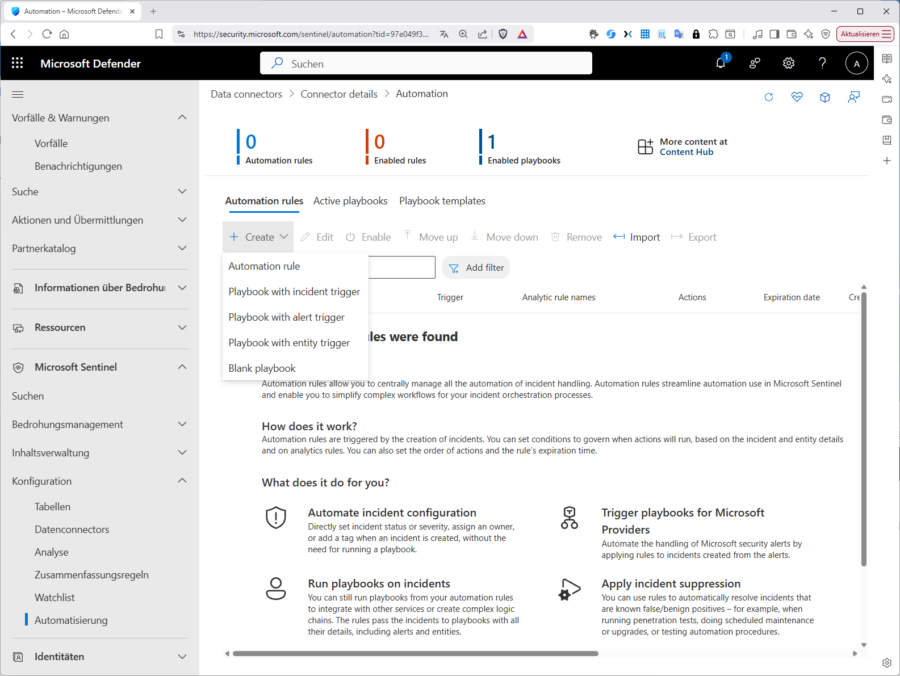
Gehen Sie indes den empfohlenen Weg über „automation-rule“ können Sie darin übrigens nicht nur Playbooks anstoßen, sondern auch den Status/Severity ändern oder „tags“ und „tasks“ hinzufügen.
Wir wollen nun und ein Playbook mit Incident‑Trigger anstupsen, das eine E‑Mail über den Office‑365‑Outlook‑Connector an das vorbereitetes SOC‑Postfach sendet und parallel einen Kommentar am Incident hinterlässt.
Möchten Sie mit einem selbst erstellen Playbook arbeiten, müssen Sie zuvor ein Solches erstellen. Ein Playbook im Sentinel-Kontext ist eine Logic App in Azure. Diese können Sie einerseits im Azure Portal (oder via PS, Azure-CLI, ARM) anlegen/definieren, es ist aber auch möglich und empfehlenswerter, die Playbook-Erstellung aus dem Defender-Portal im Sentinel-Abschnitt anzustoßen. Details hierzu würden den Rahmen dieses Beitrages sprengen. Sie finden aber Beiträge zum Thema Azure Logic Apps und/oder „Azure Logic Apps vs Power Automate“ hier im Blog.
Daher hier die Einrichtung einer Logic App im Azure-Portal in Kurzform:
- Im Azure‑Portal → Create → Logic App (Consumption- oder Standard-Plan).
- Trigger hinzufügen: Microsoft Sentinel –“ When a response to an incident is triggered” (Incident‑Trigger). Der Trigger liefert Incident, Alerts, Entities, Workspace‑Infos.
- Schritt 1: “Add comment to incident” (Sentinel‑Connector):, z. B. „Privileged role assignment detected – SOC notified“ (Audit‑Trail).
- Schritt 2: Teams, ITSM oder E-Mail:
- Microsoft Teams: „Post message in a chat or channel“ mit Incident‑Titel, Severity, TargetUser, InitiatedBy.
- ODER Office 365 Outlook – Send an email (V2) an “soc-notify@…” (wenn Mail bevorzugt).
- ODER ServiceNow/Jira: Ticket erstellen. (Alle Konnektoren sind out‑of‑the‑box verfügbar.)
- Save. (Achten Sie auf „Connections/Managed Identity“ und berechtigte Rollen, z. B. Sentinel „Automation Contributor“ für Automation Rules, „Playbook Operator“ für manuelles Ausführen.)
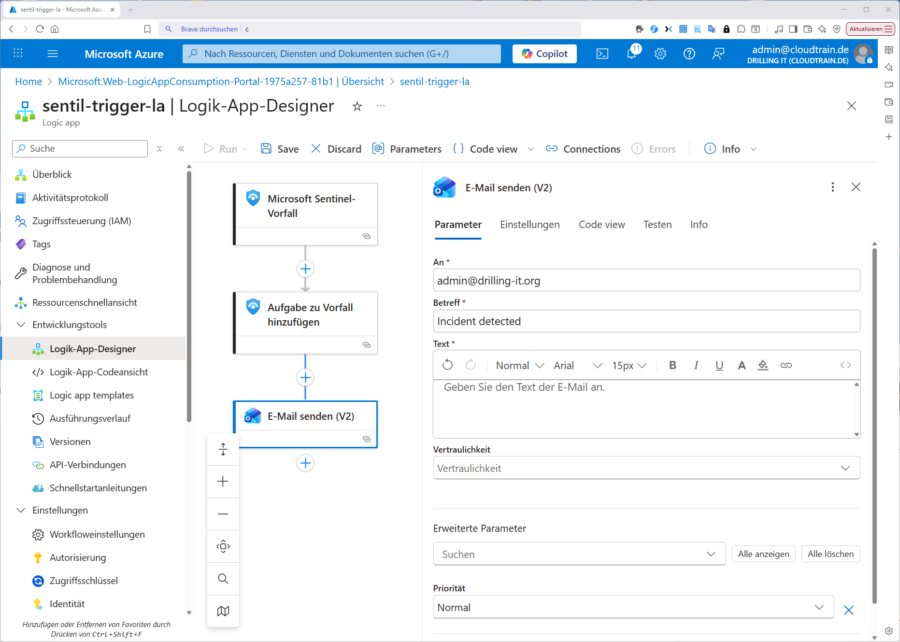
Sie sehen die Logic App anschließend auch im Defender Portal unter „Microsoft Sentinel / Konfiguration / Automatisierung“ im Tab „Active playbooks“.
Hier finden Sie im benachbarten Tab „Playbook templates“ zudem einen großen Fundus an Playbook-Vorlagen.
Nun müssen Sie nur noch ihre Logic-App/Playbook mit Ihrer Automatisch Rule verknüpfen und danach in ihrer Analyse-Regel im Schritt „Automated response“ auf diese verweisen. Wie das geht, habe ich oben bereits angedeutet. in Kurzfom:
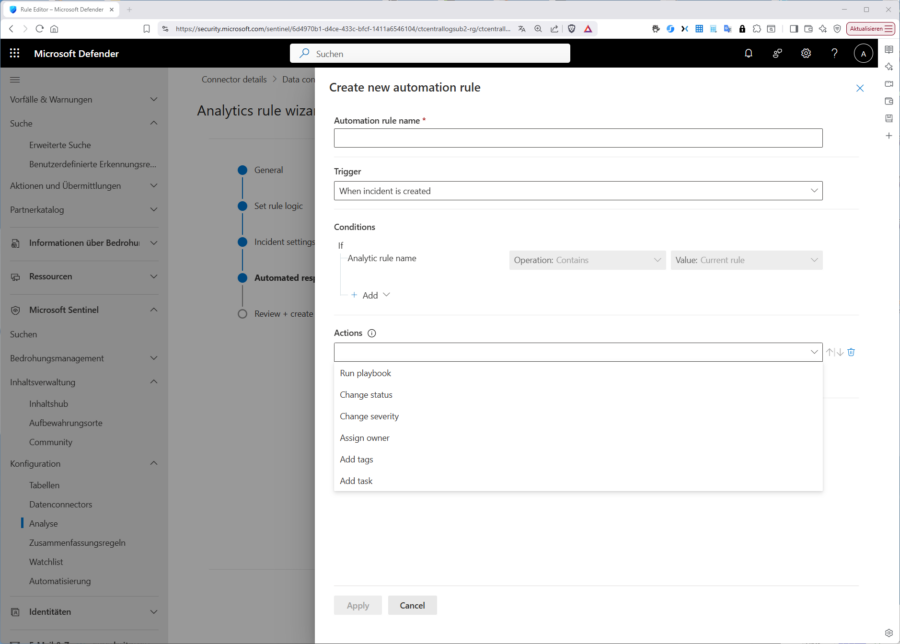
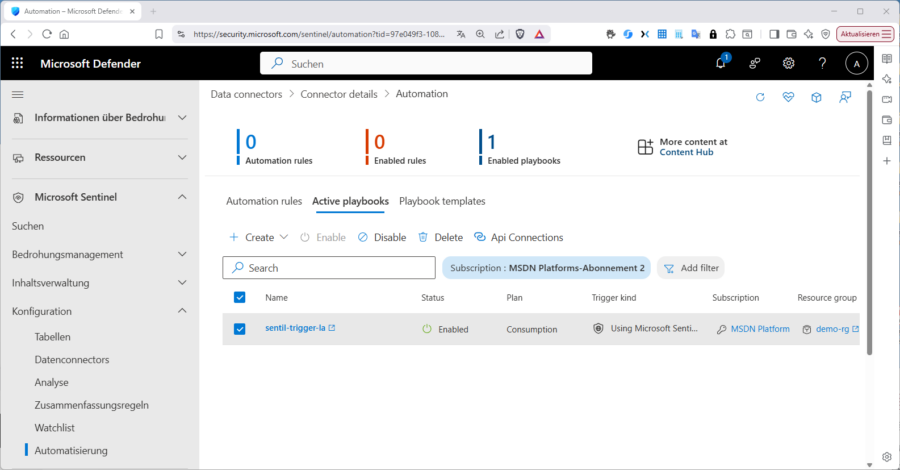
- Defender‑Portal → Microsoft Sentinel → Automation → Create → Automation rule.
- Trigger: “When incident is created” (optional: Condition Severity = High).
- Conditions: hier nicht benötigt
- Action: Run playbook → Playbook auswählen.
Order/Scope definieren → Save.
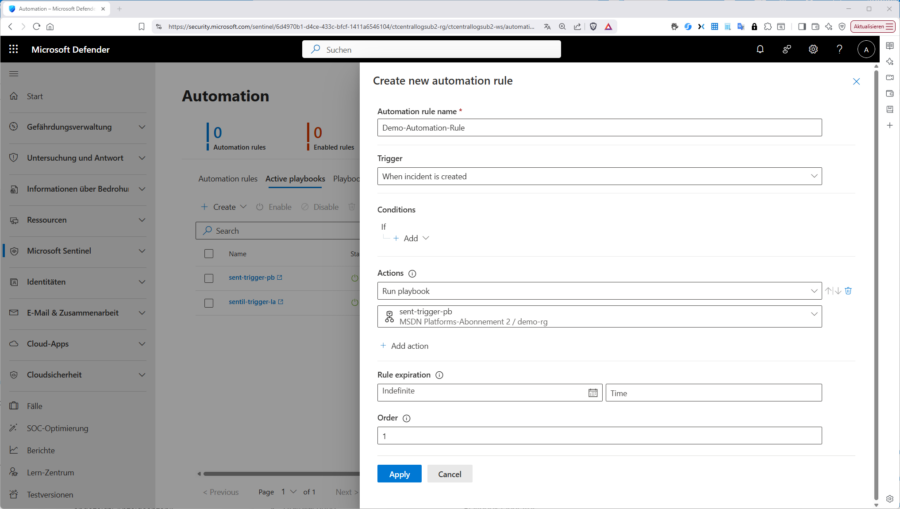
Passen Sie aber wie oben erwähnt auf bei den Berechtigungen: Selbst wenn Sie in der Evaluierungsphase als „Contributor“ oder gar „Owner“ für Ihre Subscription, Workspaces, Playbooks usw. unterwegs sind, reicht das für Automation Rules in Sentinel nicht aus. Ein Playbook, das im Sentinel Analytics Rule Wizard oder bei der Incident Automation („Automation Rules“) angezeigt wird, benötigt:
- Auf der Ressourcengruppe des Playbooks
- „Sentinel Contributor“
- “Sentinel Playbook Contributor” (falls API‑Connections dabei sind)
- Auf dem Log Analytics Workspace
- “Sentinel Contributor” oder “Sentinel Responder”, denn „Owner“ enthält diese Sentinel-Rollen nicht.
Anmerkung / Tipp: Das Beispiel mit der E-Mail ist natürlich mehr oder weniger an den Haaren herbei gezogen, um möglichst einfache Dialoge zu produzieren, denn der Fokus dieses Beitrages liegt darin, die zugrunde liegenden Workflows aufzuzeigen.
In der Praxis würde man eher so etwas wie „Kommentar + Teams statt“ konfigurieren, statt „nur E-Mail“; denn PIM verschickt natürlich in Teilen ohnehin eigene Mails. Der Mehrwert entsteht dann durch den Audit‑Trail im Incident (Kommentar) und die SOC‑Kanalisierung (Teams/ITSM). Beides skaliert im Betrieb deutlich besser.
Incident untersuchen
Haben Sie schließlich alles eingerichtet und konfiguriert, stehen Ihnen im Defender umfassende Möglichkeiten zur Incident-Untersuchung zur Verfügung. Das machen Sie im Defender-Portal unter „Untersuchen und Antwort / Vorfälle“, bzw. „Untersuchen und Antwort / Benachrichtigungen“.
Beginnen Sie mit der „Benachrichtigung/Warnung“. Hier finden Sie in den Abschnitten „Was ist geschehen“ und „Detail zur Analyseregel“ bereits hilfreiche Informationen und im rechten Teil des Fensters die Details zur eigentlichen Warnung. Außerdem können Sie direkt von hier aus mit einem Klick auf „Regel in Sentinel anzeigen“ wieder zur auslösenden Analyse-Regel wechseln.
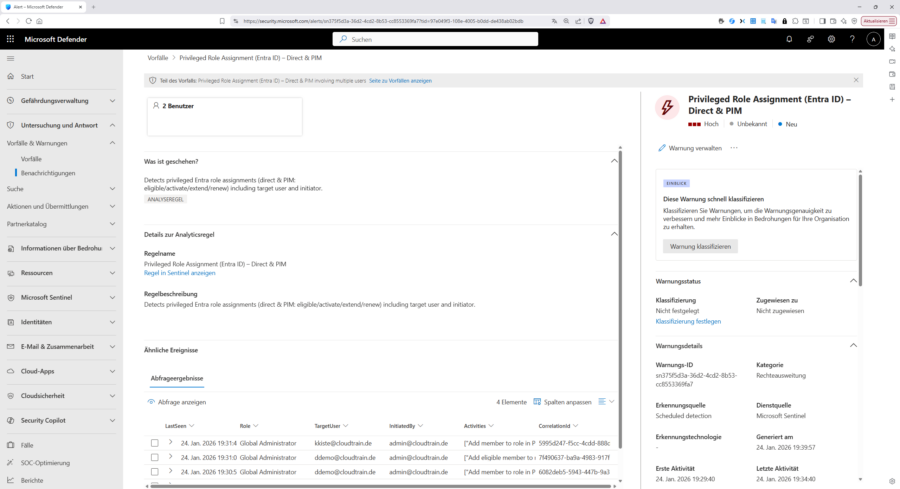
Nun klicken Sie in der Liste der „Vorfälle“ auf den Vorfall selbst und in die eigentliche Untersuchung zu wechseln. Sie laden dann im Tab „Angriffsgeschichte“ mit dem „Ereignisdiagramm“ im zentralen Bereich des Fensters und der „Prioritätsbewertung“ im rechten Teil. In unserem Fall sind 2 Benutzer betroffen; allerdings handelt es sich hier um eine reguläre Rollenhochstufung in PIM, daher die niedrige Prioritätsbewertung.
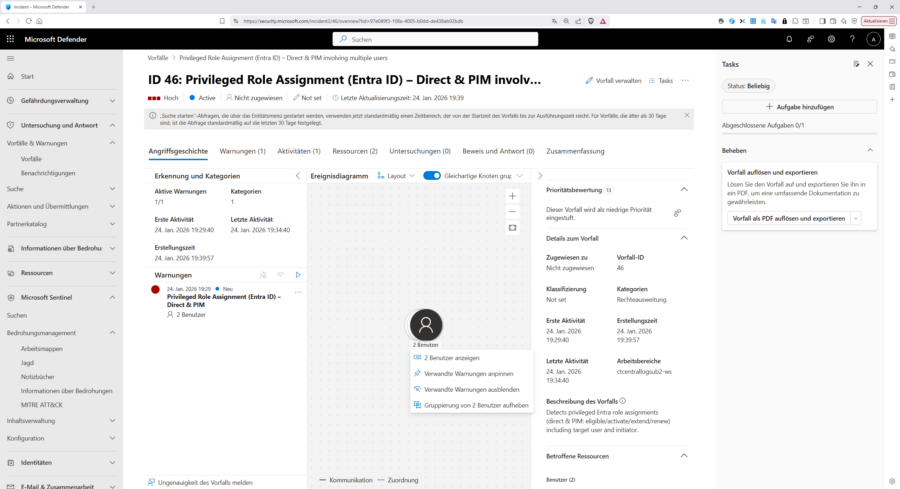
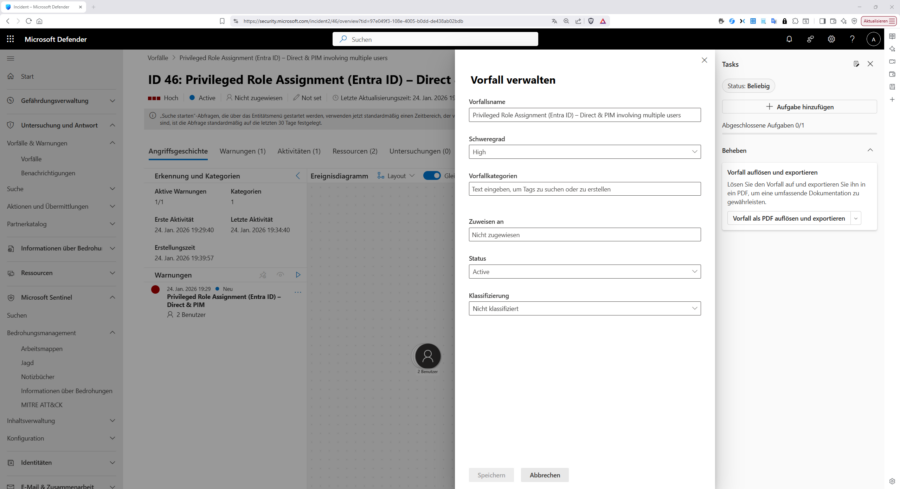
Im Tab „Ressourcen“ finden Sie dann Details zu den „betroffenen Ressourcen“, in diesem Fall „Benutzer“. Mit einem Klick auf „Vorfall verwalten“ rechts oben, können Sie ggf. Name, Schweregrad und Kategorisierung des Vorfalls ändern, den Vorfall einem verantwortlichen Bearbeiter zuweisen, den Status ändern oder eine Klassifizierung vornehmen. Sie können den Vorfall auch als PDF exportieren.
Klicken Sie im Tab „Warnung“ auf die ausgelöste Warnung landen Sie wieder in der gleichen Ansicht wie oben bei den Benachrichtigungen.
Bei anderen Vorfällen wie z. B. „Suspicious incoming RDP network activity“ (Dieser stammt allerdings nicht von Sentinel, sondern vom Defender XDR) haben Sie im Ereignisdiagramm je nach Art des Vorfalls mitunter „interessantere“ grafische Aufbereitungen.
Eine weitere umfassende Beschreibung der Analyse-Optionen sprengt allerdings den Rahmen des Beitrages, bzw. sind einem Folgeartikel vorbehalten.
Fazit
Sentinel ist dann stark, wenn man es als Plattform denkt. Die Einrichtung bleibt schnörkellos: LAW, Sentinel aktivieren, Diagnostic settings setzen. Die Komponenten greifen souverän ineinander: Connectors aus dem Content Hub, Analytics‑Regeln, Incidents, Automation Rules, Playbooks.
Die Kosten sind je nach angebundenen Quellen mitunter hoch aber stets nachvollziehbar. Die Musik spielt hier vor allem bei der Ingestion, während Automationsvorhaben ja stets „pro Run“ abrechnet werden.
Dennoch: gut gemachte, getestete Detections, wie unsere zur Rollenhochstufungserkennung, die mit KQL erklärbar sind und mit Automation sofort Wirkung erzeugen, machen die Arbeit mit Sentinel wertvoll. Hat man stets den Dreiklang ….
- saubere Datenwege,
- klare Regeln
- gezielte Reaktion
im Auge, sind die Kosten vorhersehbar und für das SOC bleibt Sentinel ergonomisch beherrschbar.